About Me
Hello! I'm Youngmin Kim. I'm currently a researcher at Yonsei University in the Medical Imaging & Computer Vision Lab, advised by Prof. Seong Jae Hwang. Previously, during my Master's course, I was advised by Prof. Youngjae Yu.
My research centers on how AI can understand videos and connect that understanding to human perception and communication, with a particular focus on nonverbal expression and sign language.
Latest News
-
Jul 2026🎉 Selected as a recipient of the Doctoral Excellence Scholarship (Science and Engineering)!
-
Jun 2026🎉 Paper accepted to ECCV 2026!
-
Feb 2026🎉 Paper accepted to CVPR 2026!
-
Jan 2026🎉 Paper accepted to Automation in Construction (IF: 11.5)!
-
Sep 2025🎓 Joined MICV Lab at Yonsei University!
-
Aug 2025🎉 Paper accepted to EMNLP 2025!
-
May 2025🎉 Paper accepted to MICCAI 2025!
-
Feb 2025🎉 Paper accepted to ACL 2025!
Publications
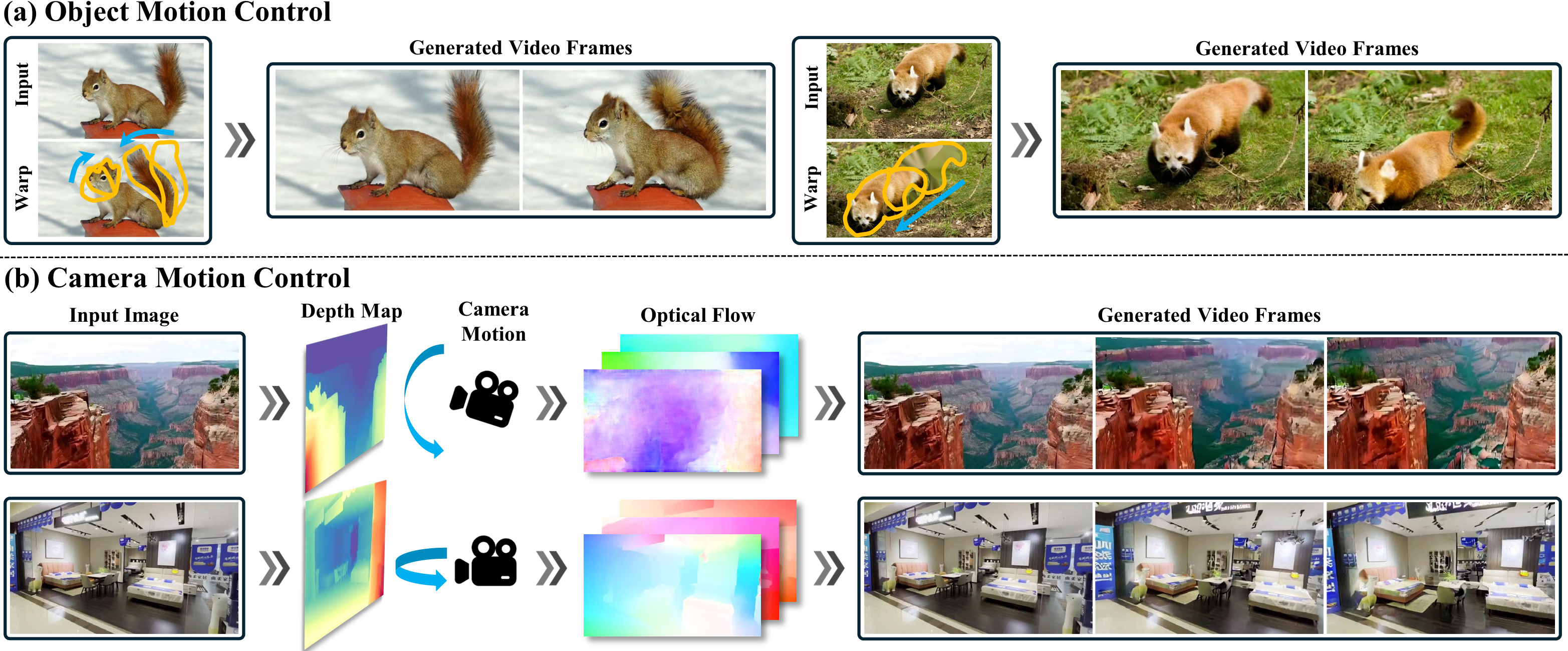
QWERTY: Training-Free Motion Control via Query-Warped Video Diffusion Transformers
TLDR; We propose QWERTY, a training-free motion control framework for image-to-video DiTs that warps semantic queries and uses self-guided latent optimization to achieve precise user-defined motion without fine-tuning.
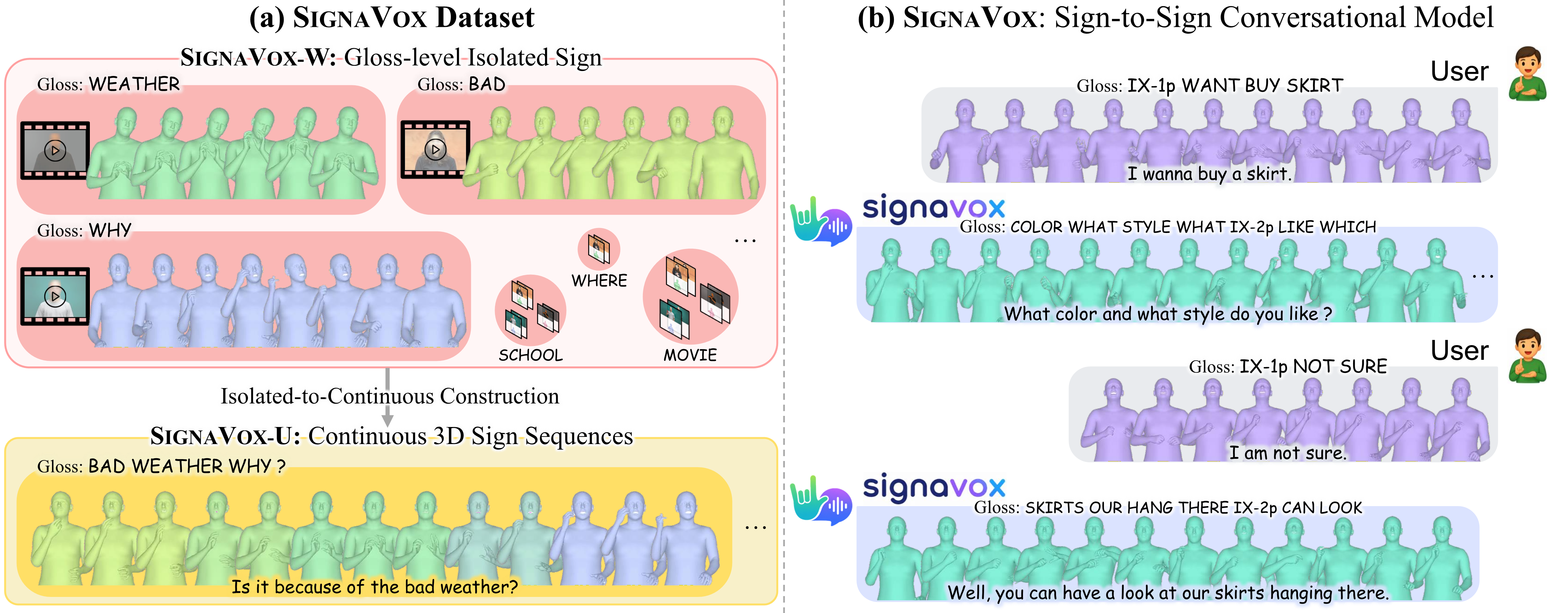
Towards Continuous Sign Language Conversation from Isolated Signs
TLDR; We propose SignaVox, a sign-centered framework that scales 3D sign conversation data from isolated signs and enables direct sign-to-sign response generation.
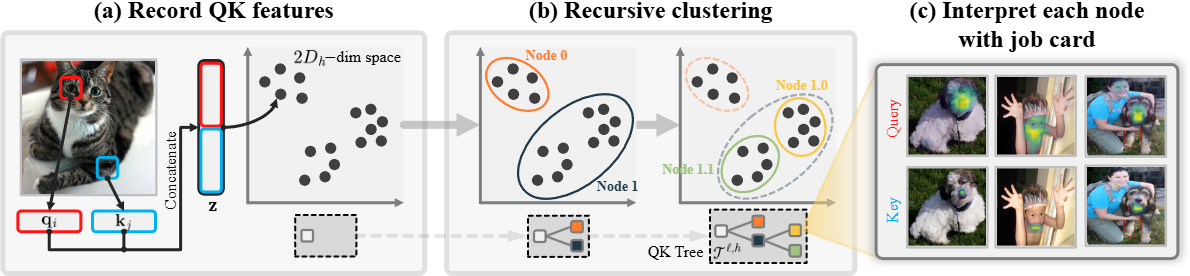
Attention Weight as a Hierarchical Tree in ViT
TLDR; We propose a QK-tree framework that decomposes ViT attention into semantically meaningful query-key pair clusters, enabling interpretable analysis and training-free object localization across diverse ViT backbones.
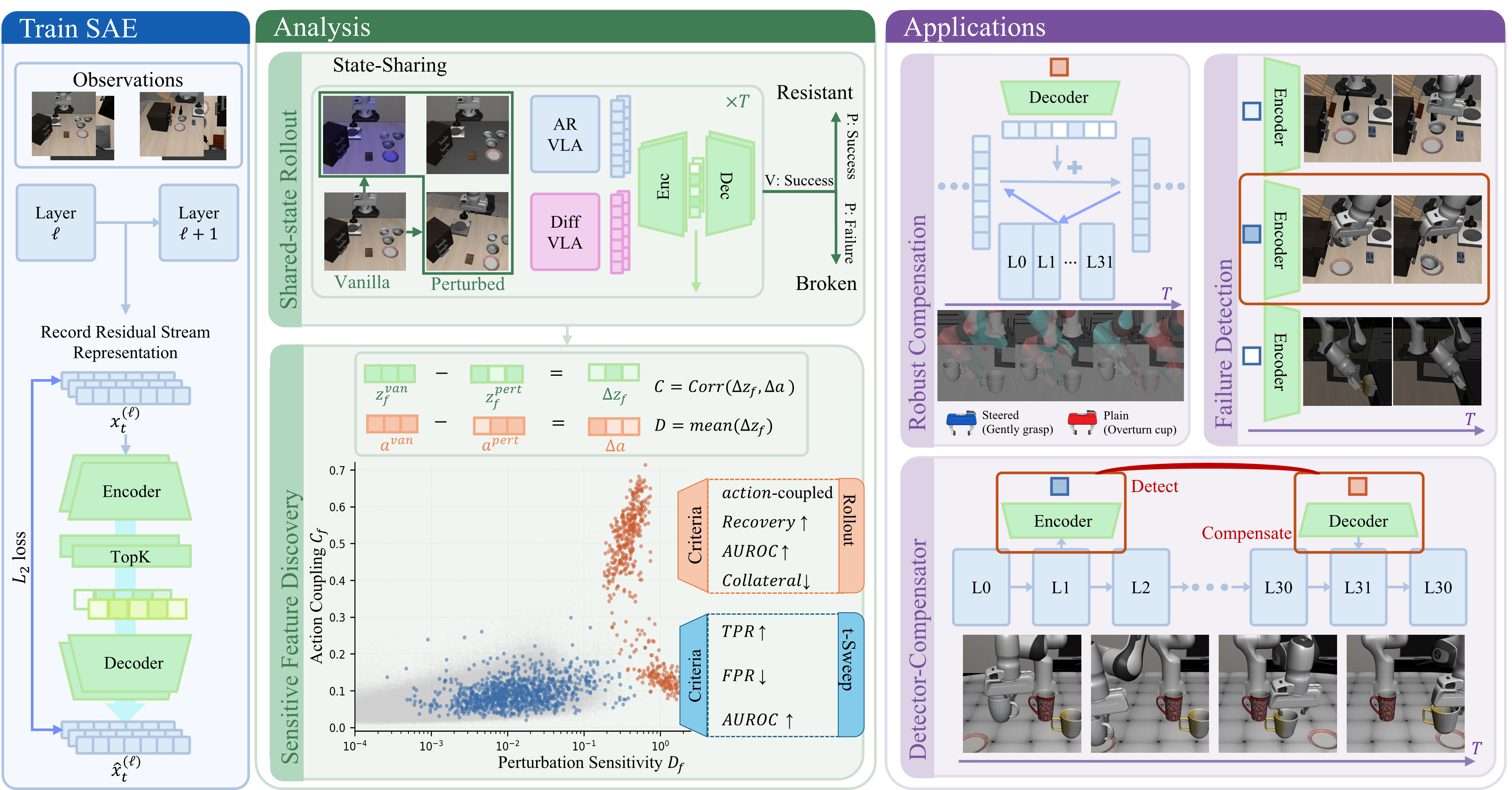
Sparse Feature Analysis and Control for Robust Vision-Language-Action Models
TLDR; We show that sparse autoencoder features can detect and mitigate visual-perturbation failures in VLA models through feature-level steering.
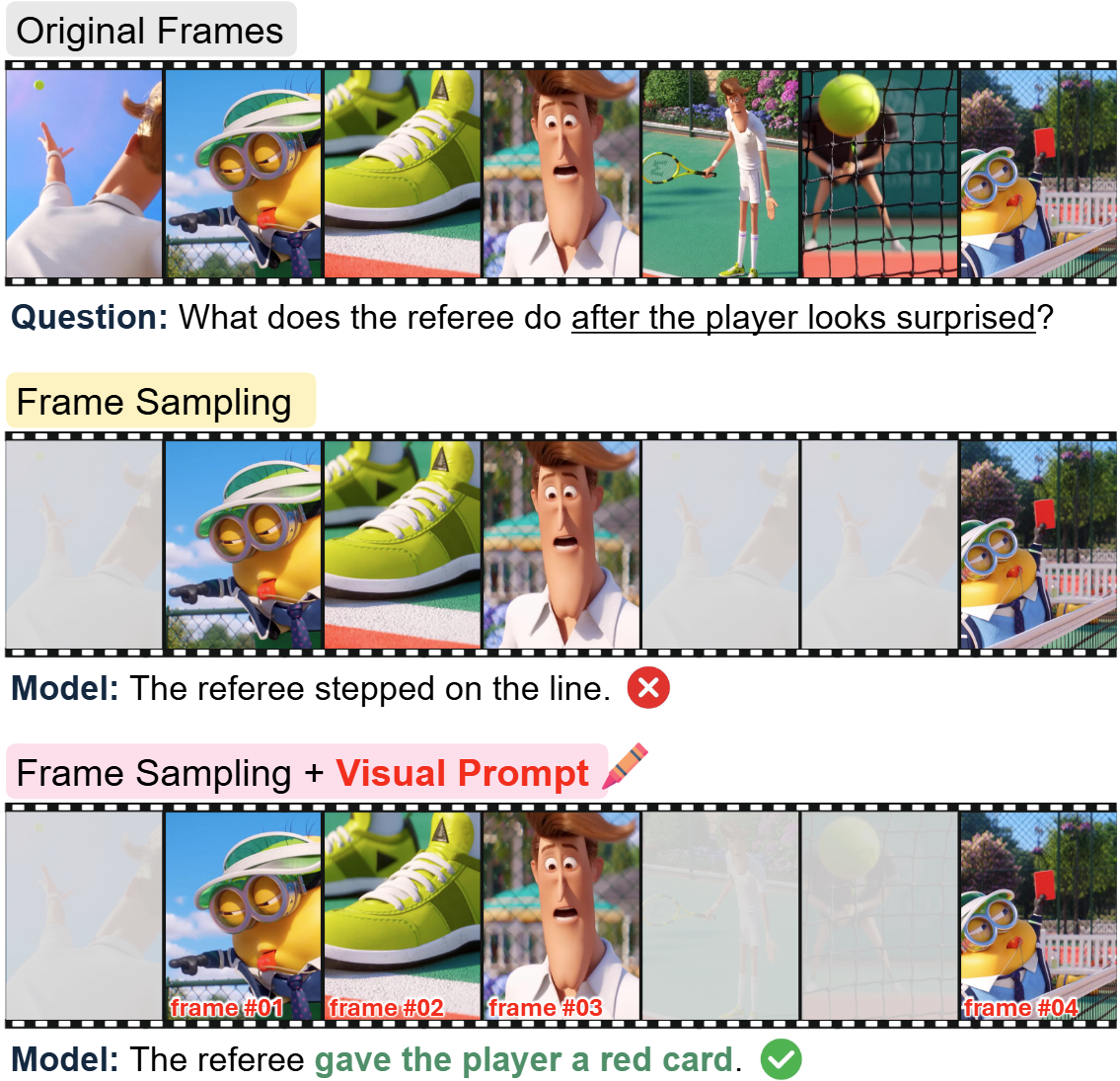
ViKey: Enhancing Temporal Understanding in Videos via Visual Prompting
TLDR; We propose ViKey, a training-free framework that enhances temporal reasoning in VideoLLMs by combining visual prompting with a Keyword-Frame Mapping (KFM) module, achieving dense-frame performance with only 20% of the frames.
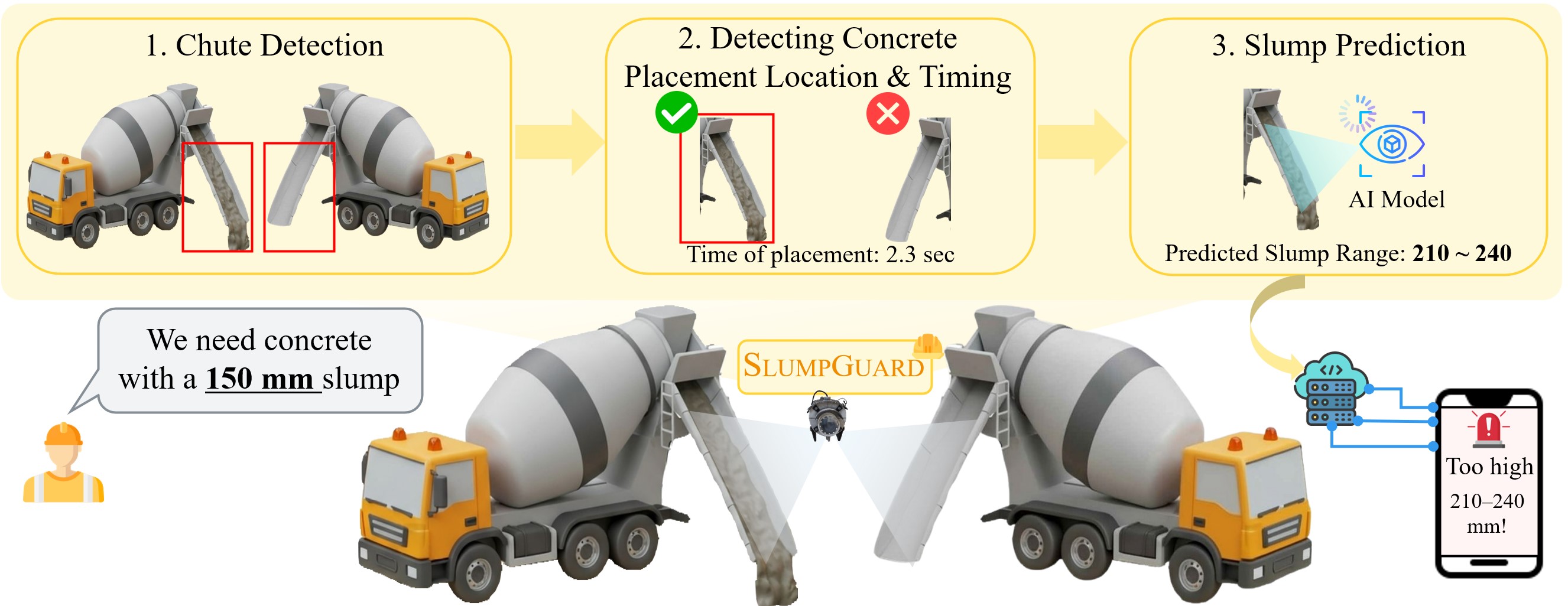
SlumpGuard: An AI-Powered Real-Time System for Automated Concrete Slump Prediction via Video Analysis
TLDR; We introduce SlumpGuard, an AI-powered, real-time video analysis system for fully automated concrete slump prediction at construction sites, supported by a large-scale dataset of over 6,000 real-world videos of concrete discharge.
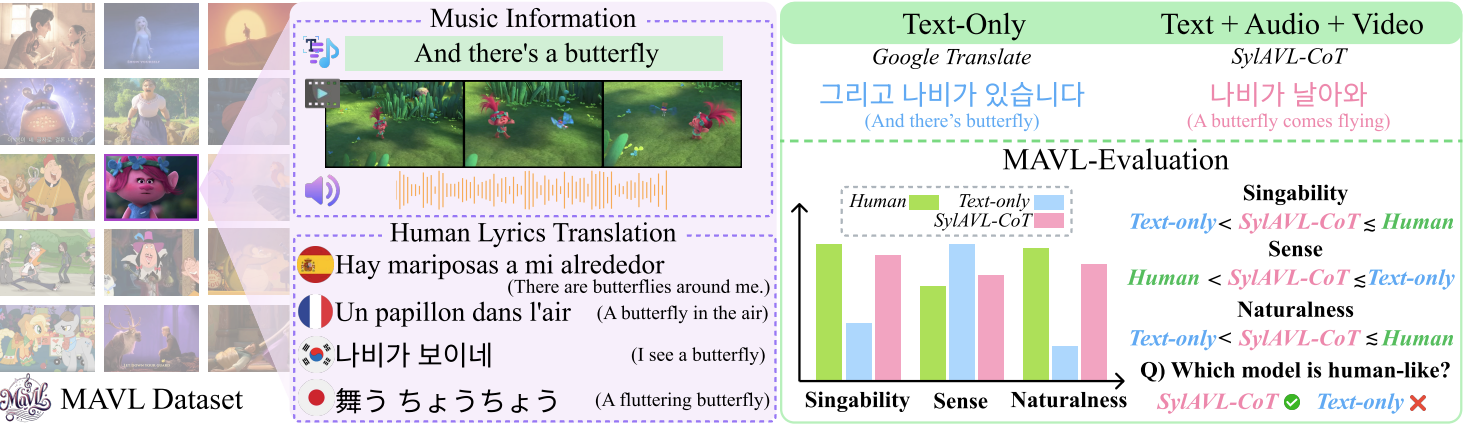
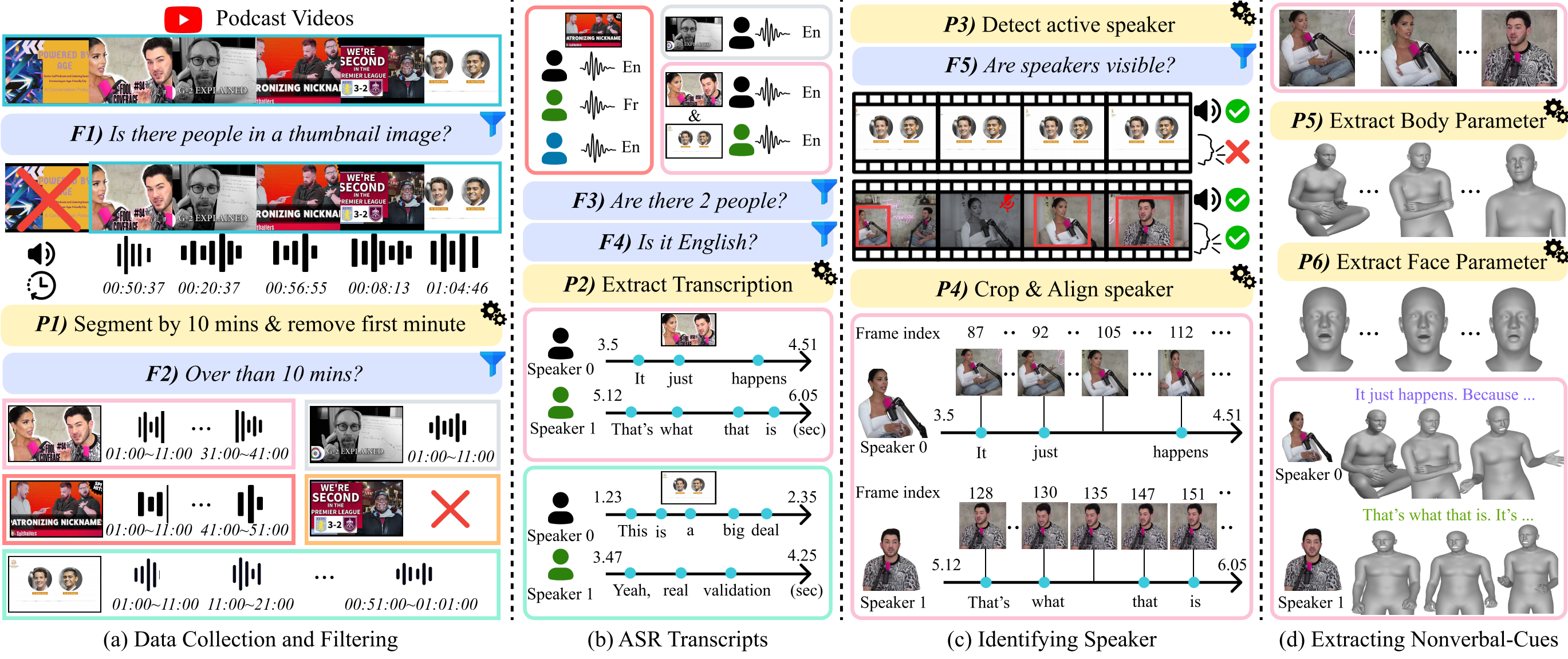
Speaking Beyond Language: A Large-Scale Multimodal Dataset for Learning Nonverbal Cues from Video-Grounded Dialogues
TLDR; We introduce VENUS, a large-scale video dataset for generating and understanding nonverbal expressions, along with MARS, a model designed to leverage it.
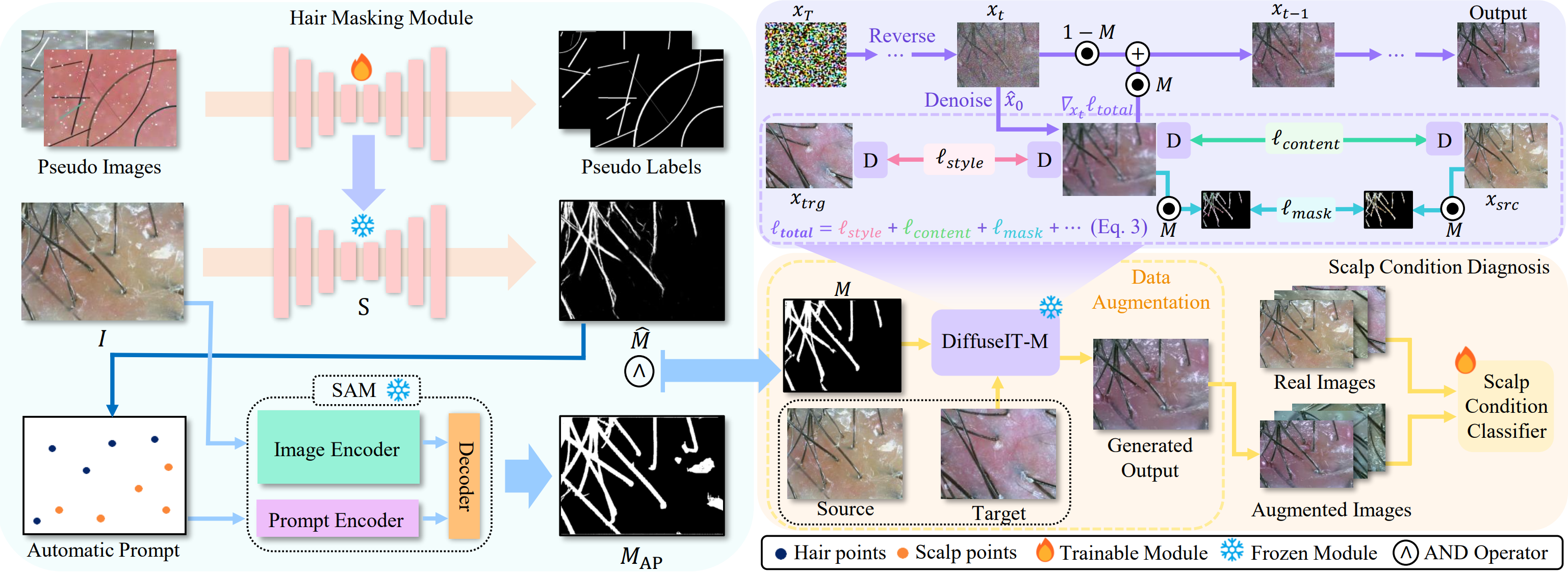
Scalp Diagnostic System With Label-Free Segmentation and Training-Free Image Translation
TLDR; We introduce ScalpVision, an AI system for comprehensive scalp disease and alopecia diagnosis that uses innovative hair segmentation and DiffuseIT-M, a generative model for dataset augmentation, to improve severity assessment and prediction accuracy.
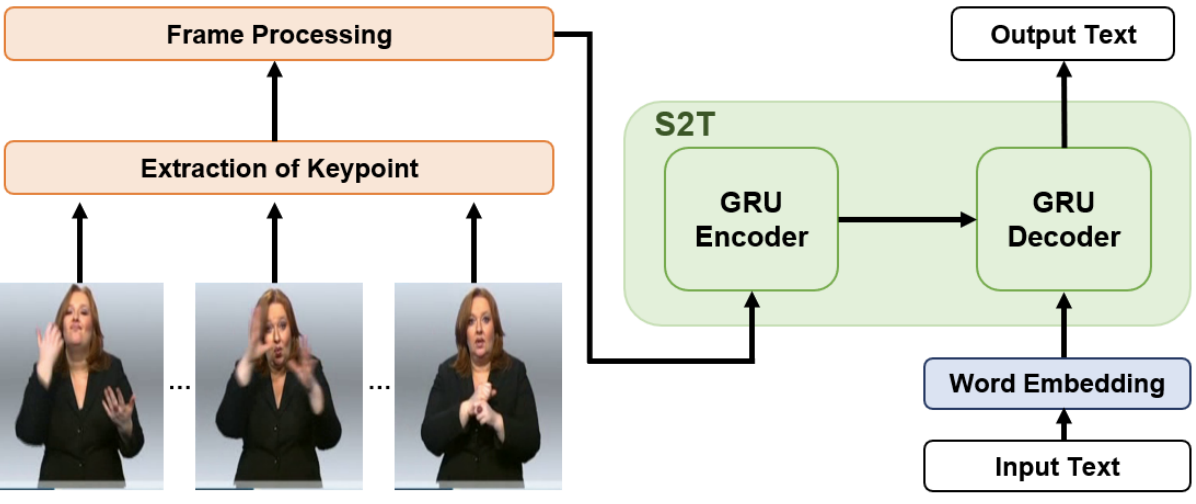
Preprocessing for Keypoint based Sign Language Translation without Glosses
TLDR; We introduce the effective preprocessing pipeline for sign language translation without glosses, combining skeleton-based motion features, keypoint normalization, and stochastic frame selection to enhance model performance.
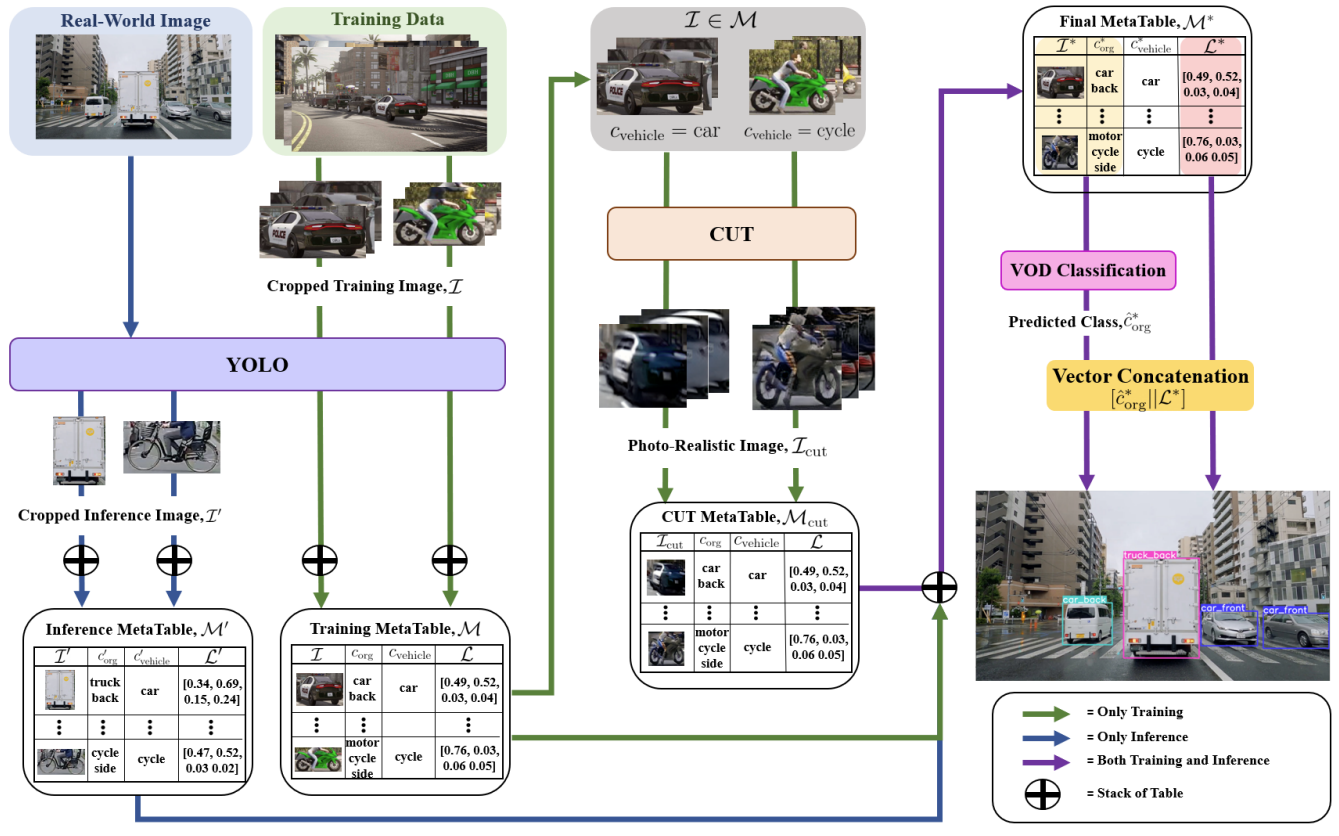
A 2-Stage Model for Vehicle Class and Orientation Detection with Photo-Realistic Image Generation
TLDR; We introduce a two-stage vehicle class and orientation detection model using synthetic-to-real image translation and meta-table fusion to improve real-world prediction accuracy.
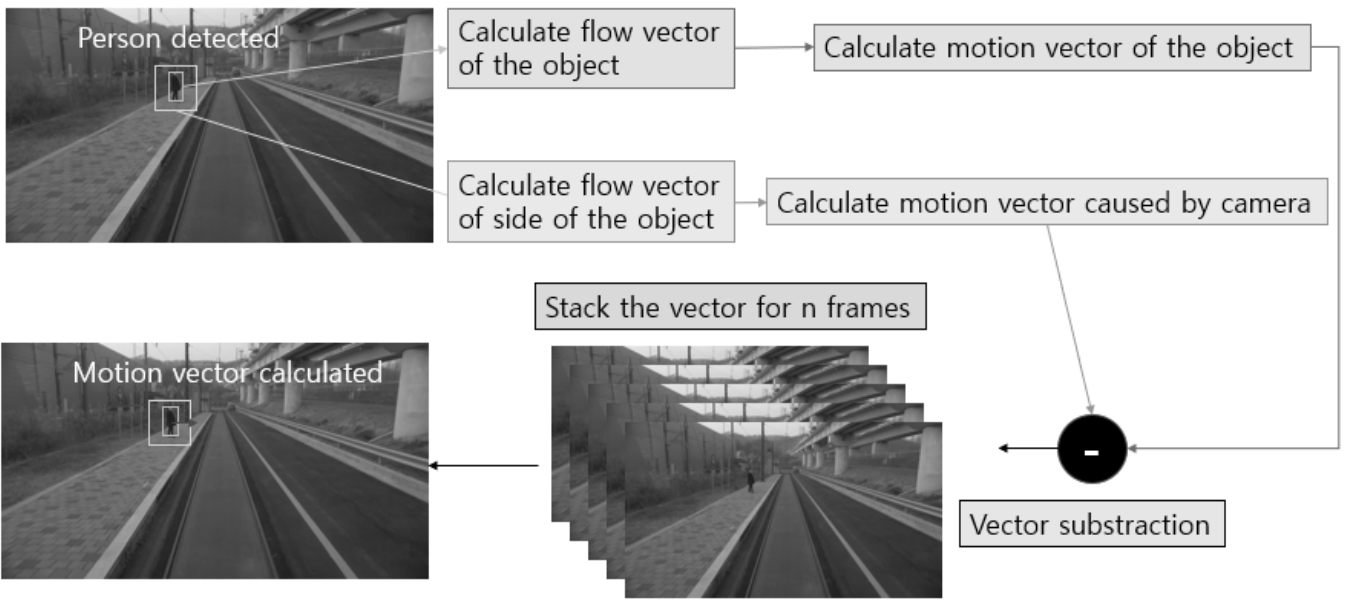
A Study of Tram-Pedestrian Collision Prediction Method Using YOLOv5 and Motion Vector
TLDR; (Korean) We introduce a real-time tram collision prediction system that combines fast object detection with YOLOv5 and a modified local dense optical flow to estimate object speed and predict collision time and probability using a single camera image.
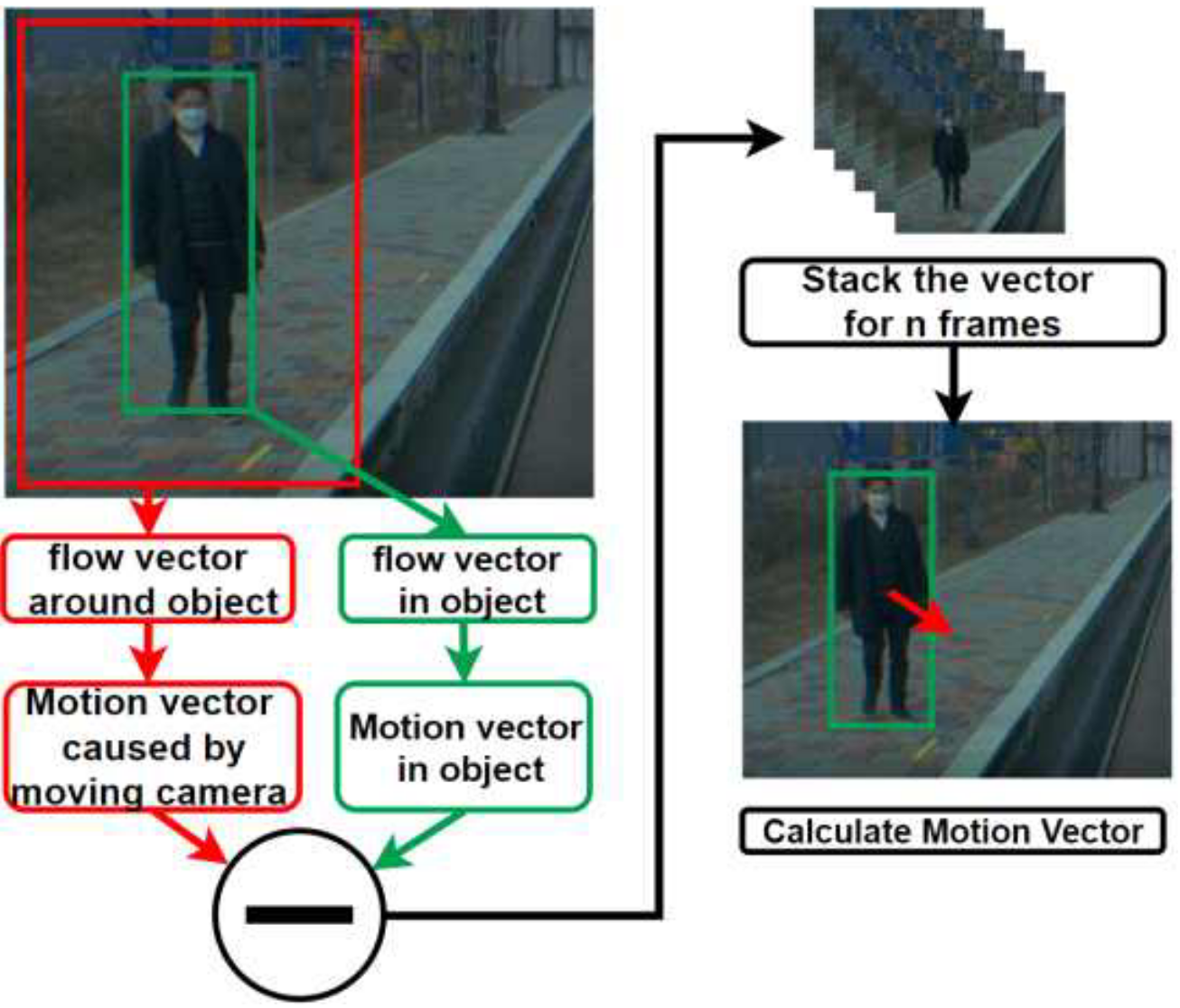
Pedestrian Accident Prevention Model Using Deep Learning and Optical Flow
TLDR; (Korean) We introduce a real-time pedestrian collision prediction system that uses YOLOv5 for fast object detection and a Local Dense Optical Flow method to quickly estimate pedestrian direction and speed, enabling accurate prediction of collision time and location.
Optical Flow Estimation Techniques and Recent Research Trends Survey
TLDR; (Korean) We survey recent advances in optical flow estimation, comparing traditional and deep learning-based methods, and highlight their applications in autonomous driving, medical imaging, and surveillance systems.
Research Experience
-
2025 — Present
Yonsei University
Graduate Research Assistant, Medical Imaging & Computer Vision Lab (MICV Lab)
Advised by Prof. Seong Jae Hwang.
-
2023 — 2025
Yonsei University
Graduate Research Assistant, Multimodal Intelligence & Robotics Lab (MIR Lab)
Advised by Prof. Youngjae Yu.
-
2021 — 2023
Incheon National University
Undergraduate Research Assistant, Real-time AI Systems Engineering Lab (RAISE Lab)
Advised by Prof. Hyeongboo Baek.
-
2020 — 2021
Advanced Institute of Convergence Technology (AICT)
Research Assistant
Advised by Ph.D Jinpyeong Kim.