
Youngmin Kim
Hello! I'm Youngmin Kim. I'm currently a researcher at Yonsei University in the Medical Imaging & Computer Vision Lab, advised by Prof. Seong Jae Hwang. Previously, during my Master's course, I was advised by Prof. Youngjae Yu.
My research question is "How can we enable AI systems to deeply understand and extract meaningful information from videos, and how can this understanding be effectively connected to human perception and communication?". I'm deeply interested in how AI can comprehend the complex and rich information embedded in videos, and how this understanding can facilitate natural interactions between humans and AI. Ultimately, I see AI as a tool designed to improve people's lives, and I believe human-AI interaction should focus on making AI more accessible and effective for users. With this perspective, I'm particularly interested in the understanding and generation of nonverbal expressions, as well as the recognition and production of sign language.
Publications
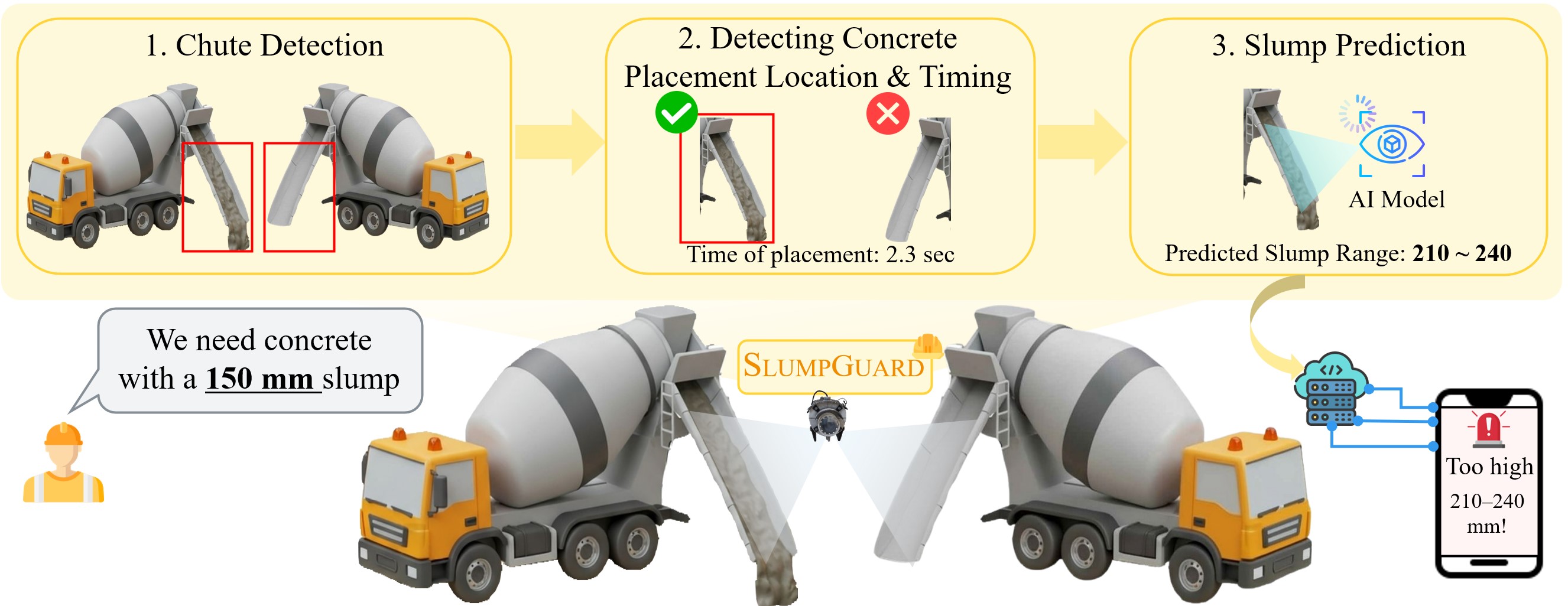
SlumpGuard: An AI-Powered Real-Time System for Automated Concrete Slump Prediction via Video Analysis
![]()
![]()
Automation in Construction (IF: 11.5)
TLDR; We introduce SlumpGuard, an AI-powered, real-time video analysis system for fully automated concrete slump prediction at construction sites, supported by a large-scale dataset of over 6,000 real-world videos of concrete discharge.
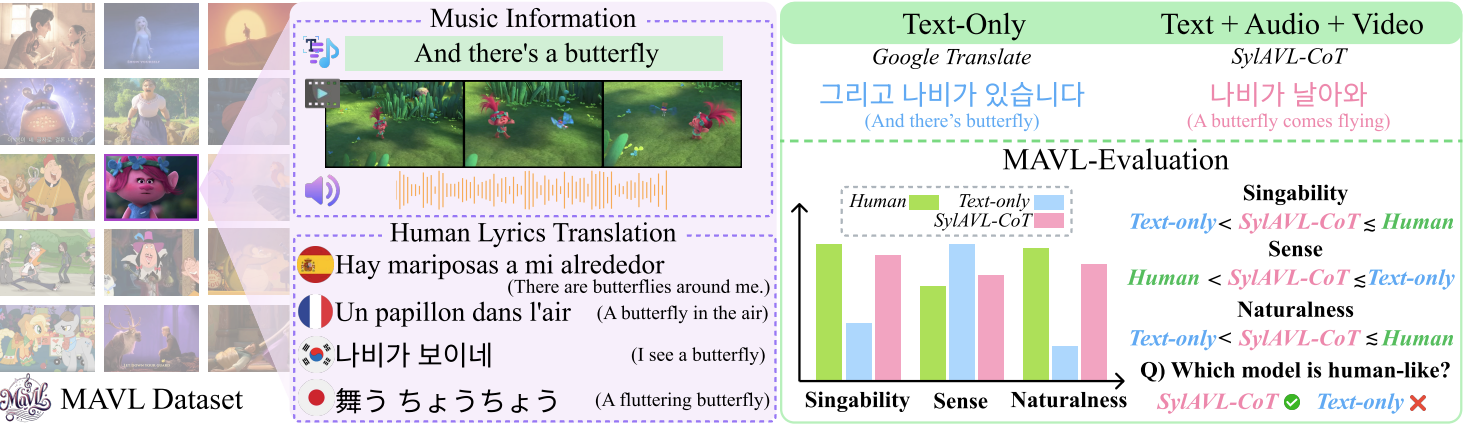
MAVL: A Multilingual Audio-Video Lyrics Dataset for Animated Song Translation
![]()
![]()
EMNLP2025 Main
TLDR; We present MAVL, a multimodal benchmark for singable lyrics translation, and SylAVL-CoT, a model using audio-video cues and syllable constraints for natural, accurate results.
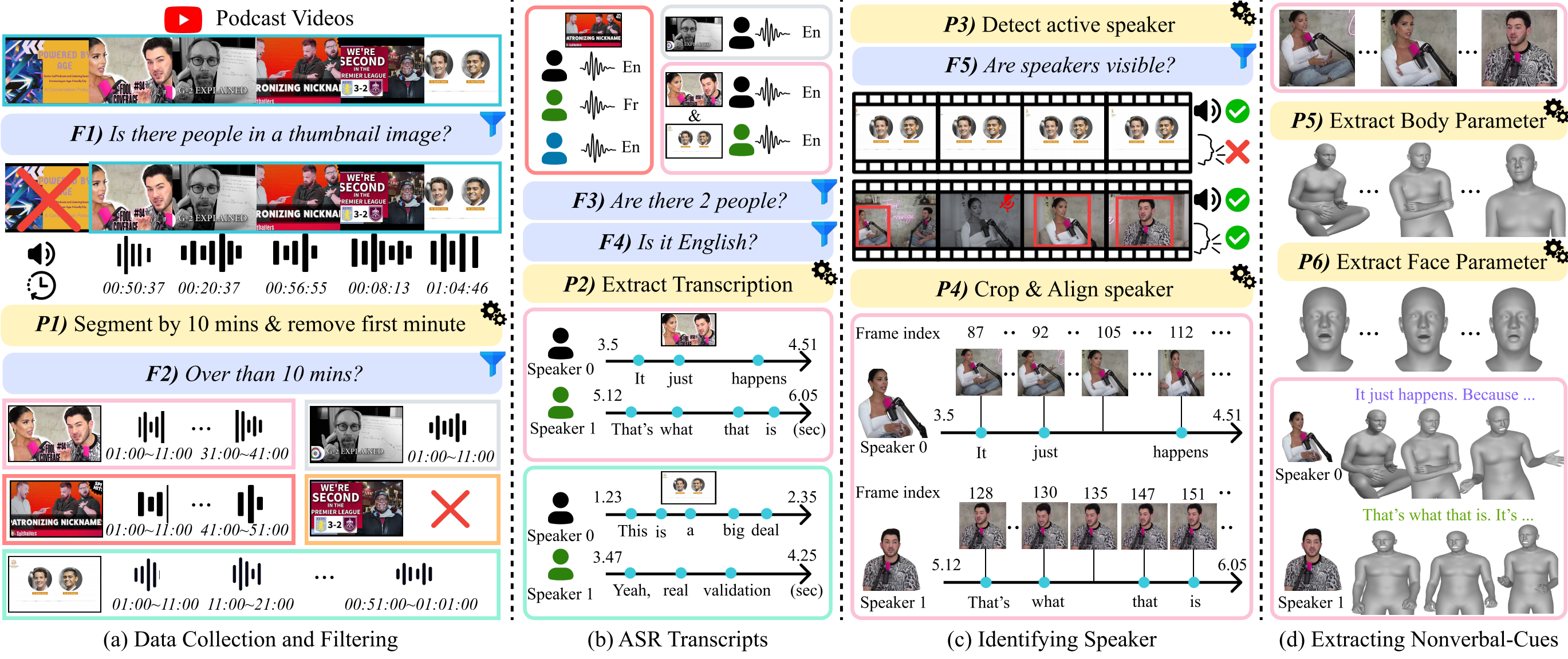
Speaking Beyond Language: A Large-Scale Multimodal Dataset for Learning Nonverbal Cues from Video-Grounded Dialogues
![]()
ACL2025 Main
TLDR; We introduce VENUS, a large-scale video dataset for generating and understanding nonverbal expressions, along with MARS, a model designed to leverage it.
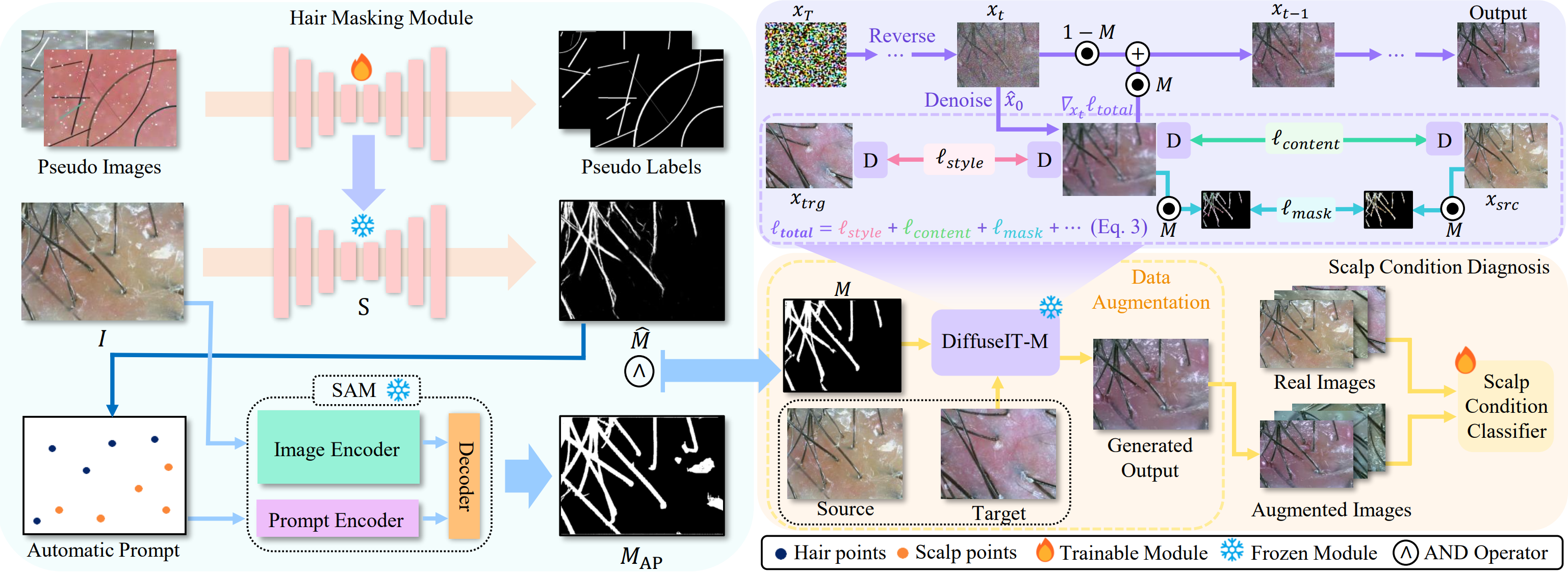
Scalp Diagnostic System With Label-Free Segmentation and Training-Free Image Translation
![]()
![]()
MICCAI 2025
TLDR; We introduce ScalpVision, an AI system for comprehensive scalp disease and alopecia diagnosis that uses innovative hair segmentation and DiffuseIT-M, a generative model for dataset augmentation, to improve severity assessment and prediction accuracy.
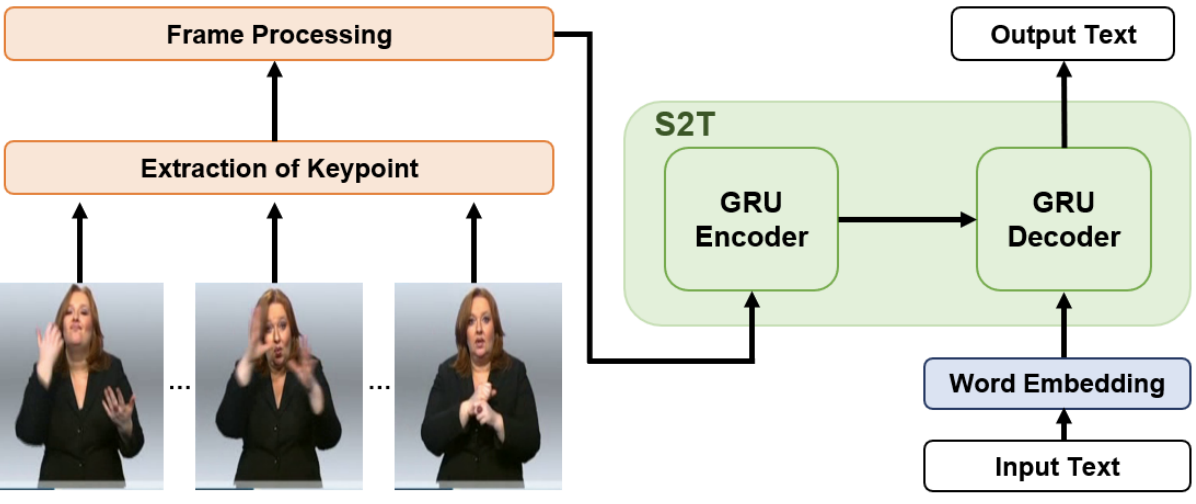
Preprocessing for Keypoint based Sign Language Translation without Glosses
![]()
Sensors (IF: 3.847)
TLDR; We introduce the effective preprocessing pipeline for sign language translation without glosses, combining skeleton-based motion features, keypoint normalization, and stochastic frame selection to enhance model performance.
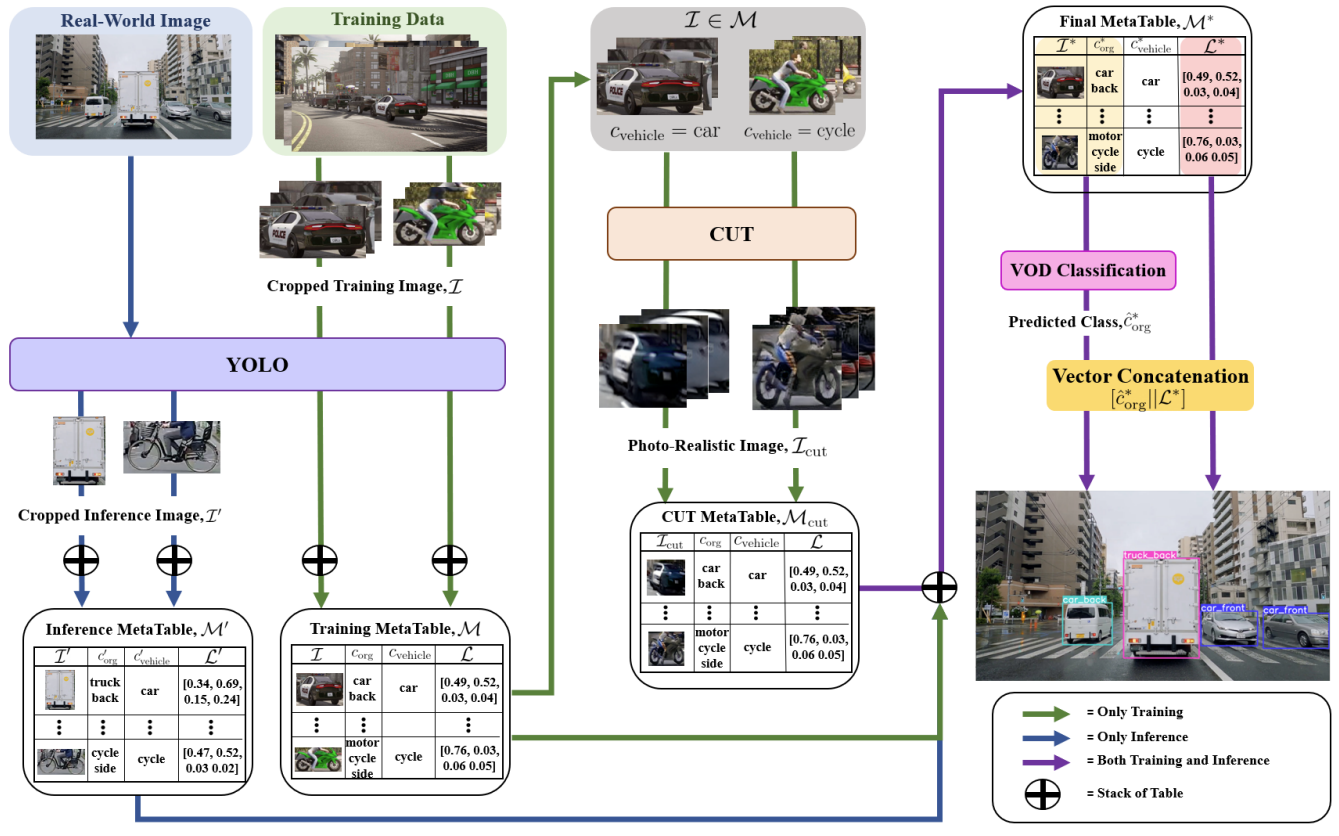
A 2-Stage Model for Vehicle Class and Orientation Detection with Photo-Realistic Image Generation
![]()
IEEE BigData 2022
TLDR; We introduce a two-stage vehicle class and orientation detection model using synthetic-to-real image translation and meta-table fusion to improve real-world prediction accuracy.
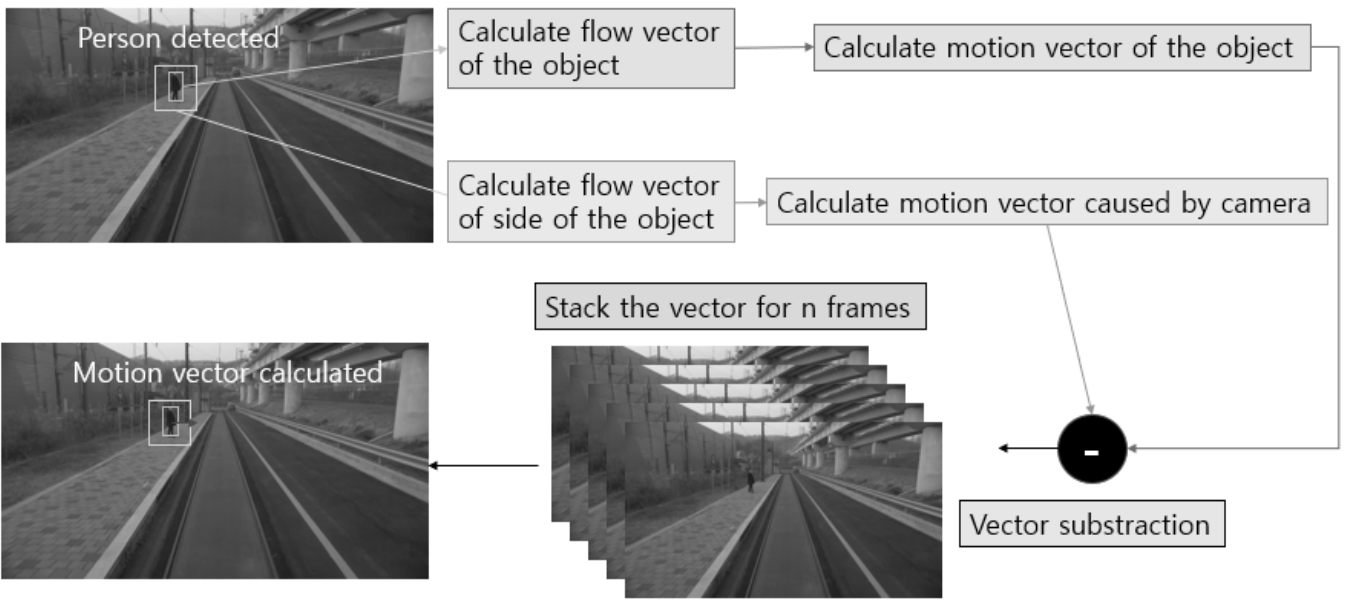
A Study of Tram-Pedestrian Collision Prediction Method Using YOLOv5 and Motion Vector
![]()
Korea Information Processing Society (KIPS)
TLDR; (Korean) We introduce a real-time tram collision prediction system that combines fast object detection with YOLOv5 and a modified local dense optical flow to estimate object speed and predict collision time and probability using a single camera image.
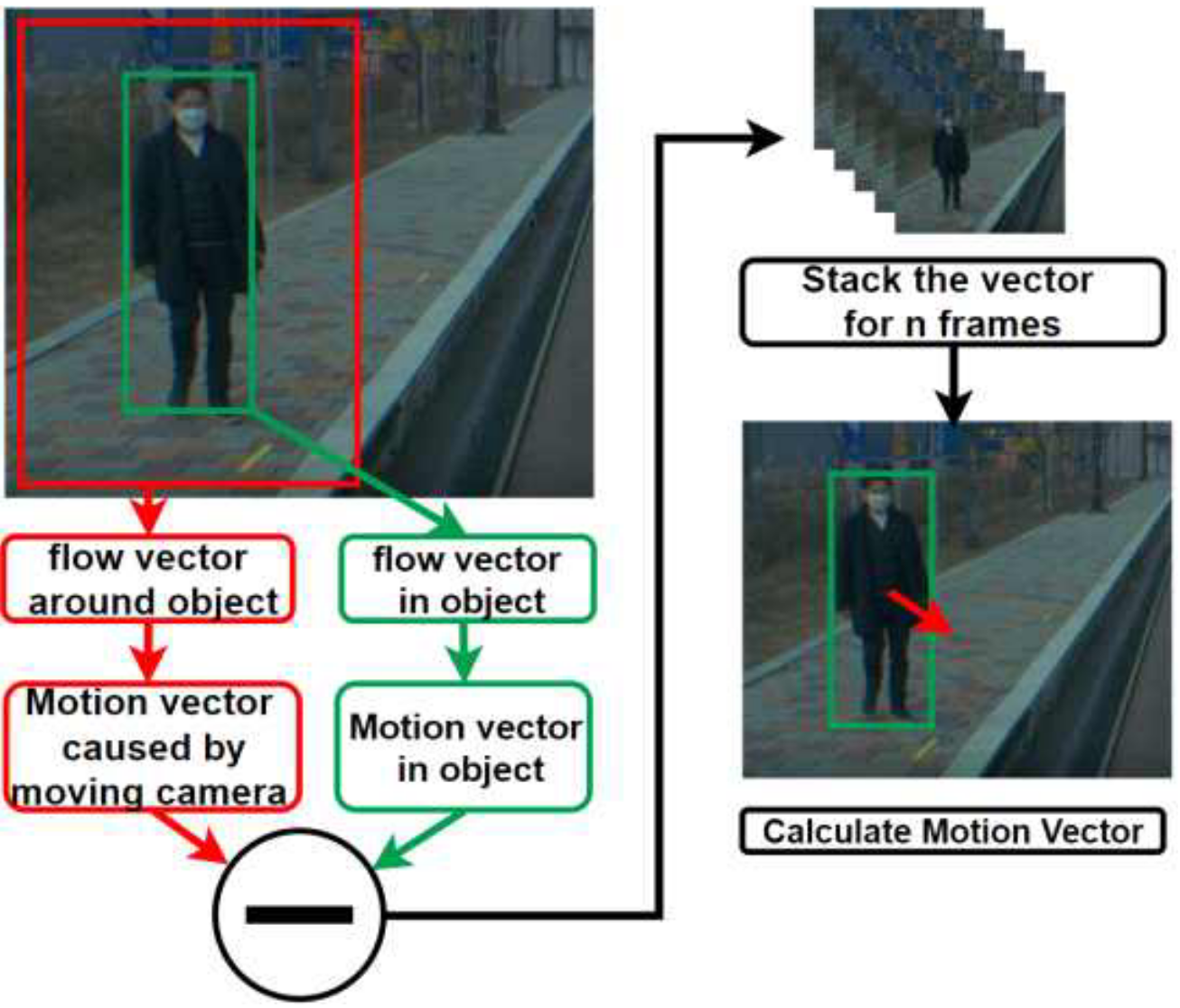
Pedestrian Accident Prevention Model Using Deep Learning and Optical Flow
![]()
Korea Computer Congress 2021 (🥇Best Paper Award)
TLDR; (Korean) We introduce a real-time pedestrian collision prediction system that uses YOLOv5 for fast object detection and a Local Dense Optical Flow method to quickly estimate pedestrian direction and speed, enabling accurate prediction of collision time and location.
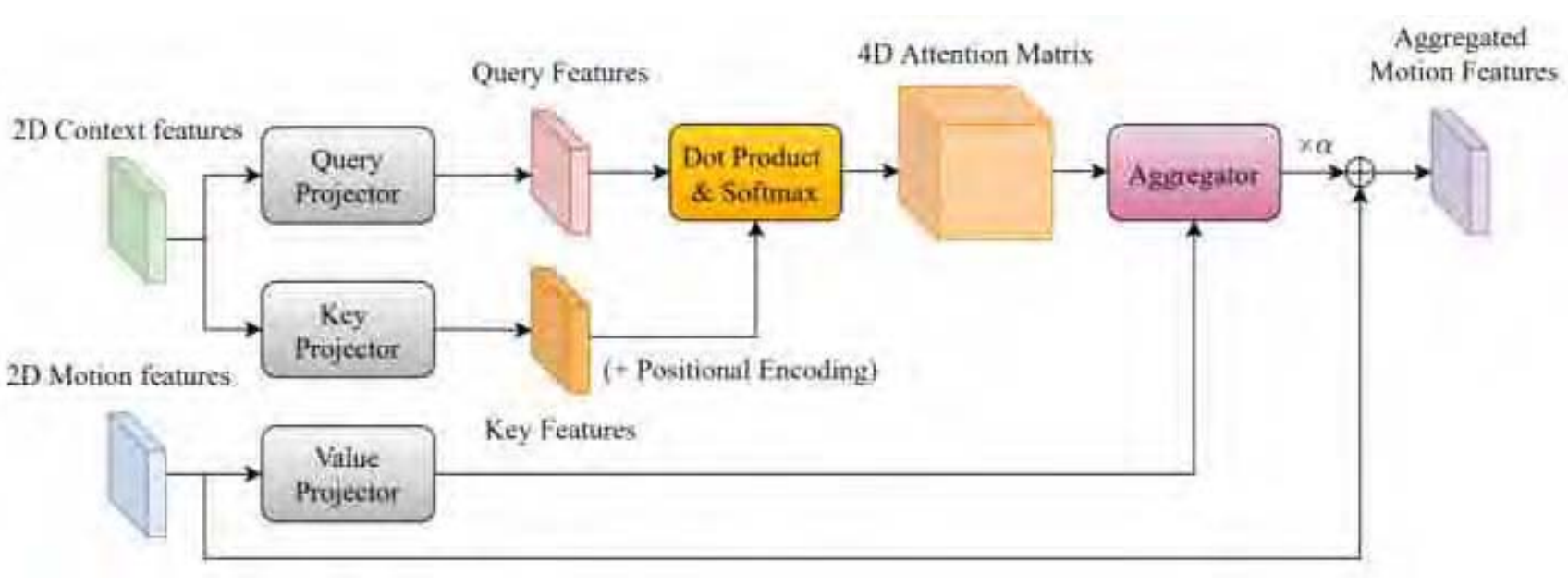
Optical Flow Estimation Techniques and Recent Research Trends Survey
![]()
Korea Information Processing Society (KIPS) Special Session
TLDR; (Korean) We survey recent advances in optical flow estimation, comparing traditional and deep learning-based methods, and highlight their applications in autonomous driving, medical imaging, and surveillance systems.